
De volta ao teste das palavras cruzadas…
Meu objetivo não é criticar e muito menos dizer qual modelo é melhor que o outro, porque, se pararmos para pensar, não dá para tomar posição entre modelos da mesma geração. Mas é possível acompanhar a evolução.
Já há algum tempo faço testes solicitando aos modelos LLM, em suas versões de chatbot, a criação de palavras cruzadas simples e analisando os resultados. Desde o começo, lá atrás, eu achei que seria algo trivial para os modelos; afinal, são treinados com palavras, funcionam como jogos de palavras “adivinhando” a próxima palavra. O fato é que a tarefa se mostrou árdua para eles e para mim — no meu caso, não pela dificuldade em olhar as péssimas respostas que eram fornecidas, mas pela decepção.
Já se passaram meses desde que fiz o último teste. Alguns modelos sofreram atualizações, outros tiveram melhorias em camadas entre a solicitação do usuário ao chatbot até que ela seja de fato processada pelo LLM. Então, temos que tomar um cuidado maior — e já adianto que não tomei — no sentido de que alguns chatbots, ou talvez todos, tentem usar ferramentas de terceiros, pesquisas em sites, para responder como se isso fizesse parte do seu raciocínio. Vi isso claramente no Grok, que pulou rapidamente para uma busca na internet e depois fez alguns testes e tentativas em sites especializados em crosswords.
Não vou dizer que o comportamento acima diminui o modelo ou o torna mais inteligente, pois isso é relativo. Mas, ao se tratar de medir a capacidade de resolução de um problema, o resultado pode ser contaminado por pipelines ou gambiarras humanas — mas “não importa”.
O importante são os resultados e, como sempre, que cada um faça suas análises e crie outros testes que sejam medidas melhores do que as padronizadas para avaliar os modelos. Assim, evita-se o que já aconteceu na indústria dos microprocessadores, onde alguns fabricantes otimizavam os chips para obter alta pontuação em determinados testes, mas que, no final, não se traduzia em bons resultados para os usuários.
Mas vamos aos resultados. Observem que a solicitação é simples: não há engenharia de prompt do tipo “Você é um especialista em… blá blá blá”. Não; o objetivo é ser simples. Não é a NASA ANALISANDO..
Pela ordem Grok: (Decepção pura)
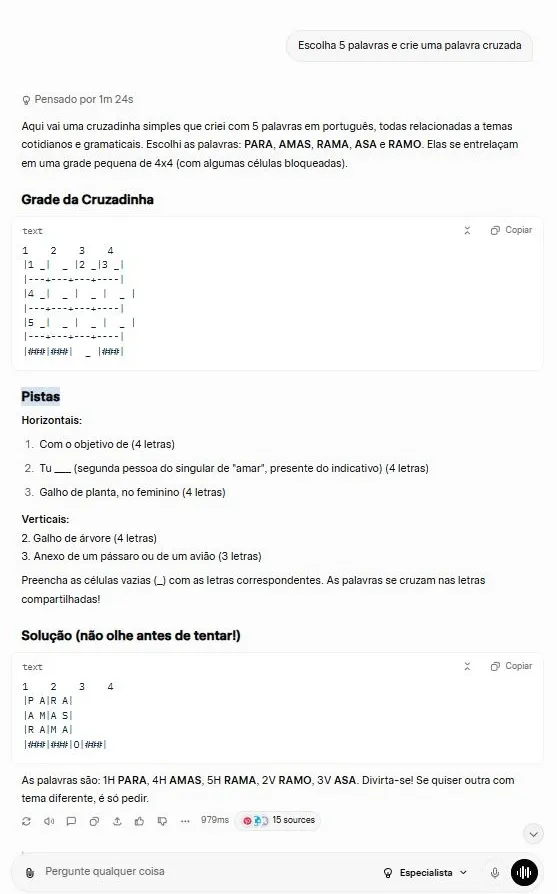
Em seguida, temos o Claude Sonnet 4.5 Estendido (não testei o 4.6). Erro feio, sim, mas o Claude é tipicamente uma ferramenta de programador: você pede a ele uma receita de pudim e ele manda um programa para receitas de pudim. Ele é, sem dúvida, na minha opinião, o melhor em geração de código, mas palavras cruzadas, que é a nossa medida de evolução…
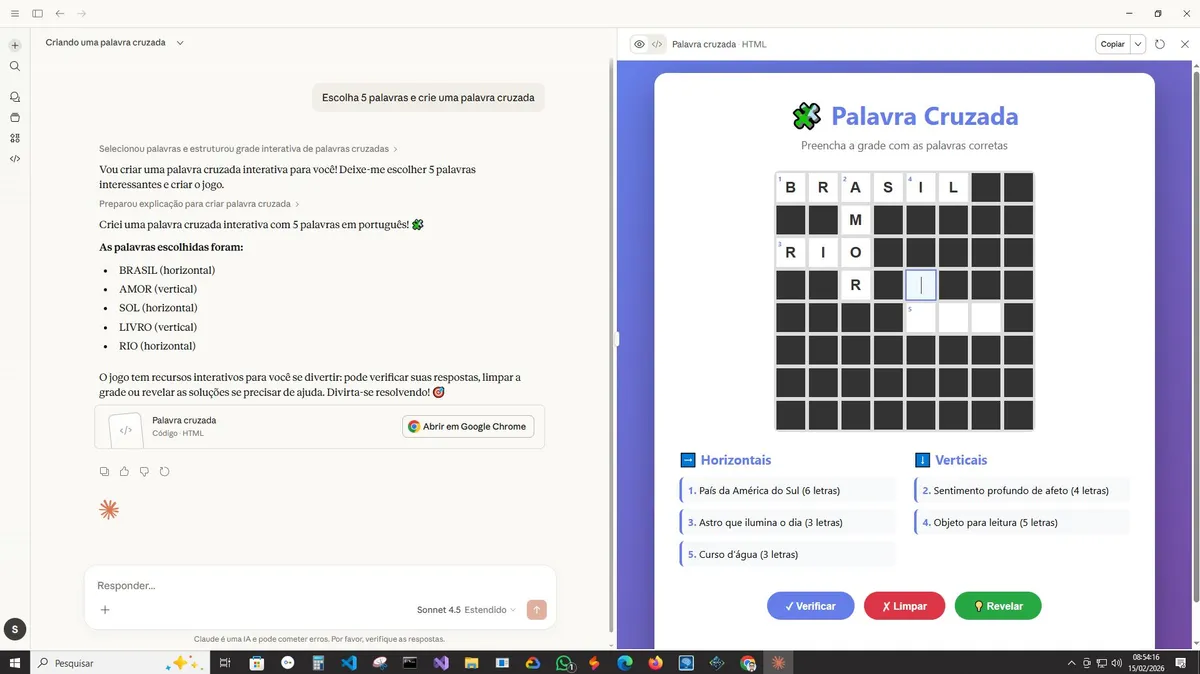
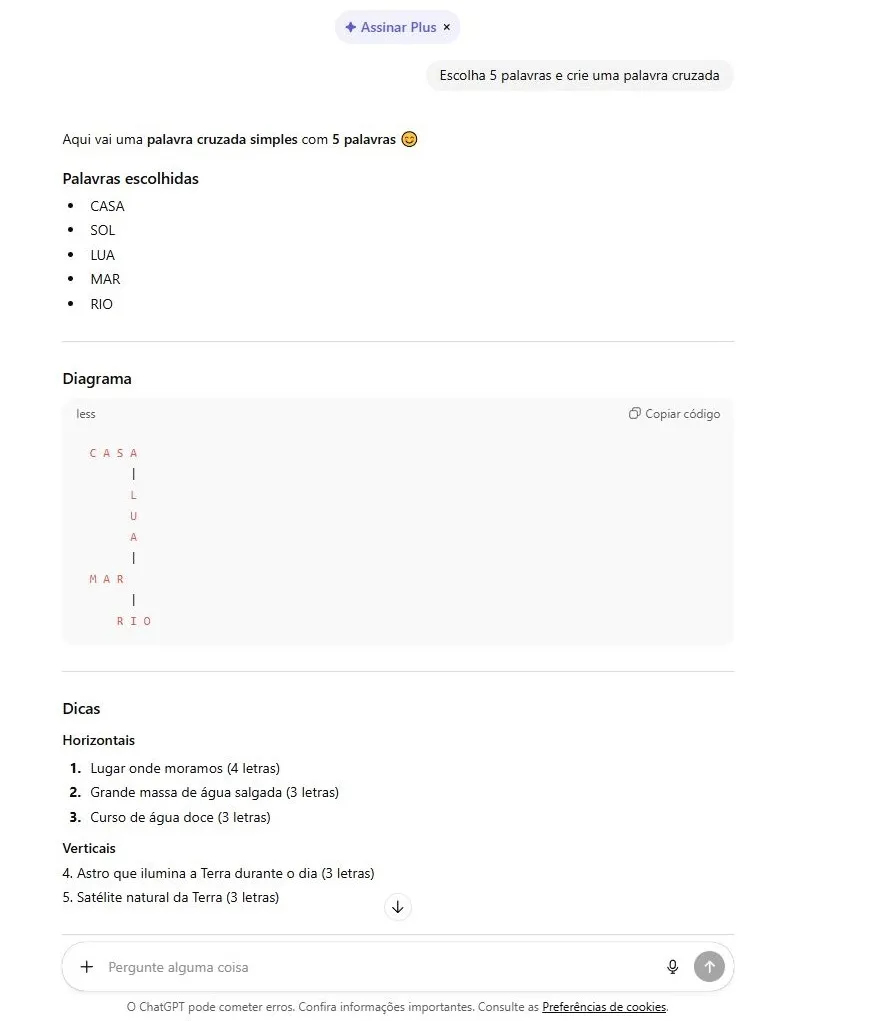
Agora temos o ChatGPT 5. Mudaram a interface do chatbot, então aparecem duas versões: a ChatGPT e a ChatGPT Go. Esta última é paga e não testei, e não está claro qual modelo está por trás das duas. Mas o teste é do chatbot usado em massa. Aqui vou ressaltar uma coisa: não vi nenhuma melhora desde o último teste, porque já existia, nos primeiros testes, um enviesamento nas palavras escolhidas — SOL, MAR, LUA — e o ChatGPT está no mesmo lugar, com o mesmo viés, e não melhorou nada. A resposta mostra que ele não sabe que, em uma palavra cruzada, as palavras devem se cruzar.
bs.: Tenho um tom mais crítico com o ChatGPT, devido à empresa estar entregando muito menos do que prometeu.
E, por fim, deixei a grande surpresa agradável, totalmente esperada. O Gemini 3.0 Raciocínio: veja, ele não se enviesou na escolha das palavras e cumpriu a tarefa brilhantemente. Isso é, de fato, uma comprovação do quanto os modelos do Google e a própria empresa estão avançando e se destacando em relação aos seus concorrentes. É lógico que o Google tem, na sua própria infraestrutura, o conhecimento armazenado; tem muito mais informação do que as outras empresas e, o mais importante, desde os primórdios lida com dados em níveis mundiais. Aqui, talvez, apenas alguma empresa chinesa ou governo tenha capacidades semelhantes. Mas o que importa é o resultado, que é a nossa medição de evolução:

Um lembrete importante é que este teste tem como objetivo, digamos, “oculto”, mostrar que, se modelos falham em escolher cinco palavras e montar um joguinho simples, imaginem o potencial de falhas em tarefas complexas, com dezenas ou centenas de pontos críticos ou sensíveis — algo extremamente perigoso.
É por isso que testes simples são importantes, pois as grandes empresas não veem uma forma de monetizar certos tipos de problemas; é melhor treinar o modelo extensivamente em moléculas e na criação de novos materiais do que em resolver palavras cruzadas.
Aos cientistas, lembrem-se de que uma das formas de resolver determinados problemas é a transformação, a troca de contexto e, depois, a aplicação da solução ao problema original. Se um modelo não consegue criar um jogo de palavras cruzadas, que se baseia em regras simples e interseção, como, por exemplo, poderíamos confiar na capacidade de um modelo em determinar que uma combinação de medicamentos, se usada, poderia ter um efeito (desejado ou não), as famosas interações medicamentosas?
A conclusão é que, independentemente de quem conseguiu concluir a tarefa, ela foi concluída com êxito e mostra um amadurecimento das ferramentas e uma melhor qualidade nas respostas. Agora, medir o quão grande foi o avanço e quanto ele é realmente do modelo, e não do pipeline, já é uma tarefa bem maior e mais complexa.
No mais… é isso.
Sandro Herculino da Silva 15/02/26